sudo python environ 环境变量问题
如果用sudo执行python命令的话,会发现:
1 | import os |
得到的变量和普通权限得到的不一致,即使是sudo加上-E参数也没有用。 这是sudoers的默认行为导致的,解决方案:
sudo visudo,Defaults env_reset改为Defaults !env_reset。 注意,加了!号。 同时注释掉Defaults secure_path,改完记得注销一下。
不需要以sudo执行python的时候记得改回来,防止出现权限安全问题。
这个奇葩的问题Google居然搜不到,看来是个神坑,分析过程如下:
既然问题的根源是sudo -E python都无法继承当前的环境变量,那么首先man sudo搜索-E参数,发现是这么写的:
-E, –preserve-env Indicates to the security policy that the user wishes to pre‐ serve their existing environment variables. The security policy may return an error if the user does not have permis‐ sion to preserve the environment.
感觉这句
The security policy may return an error if the user does not have permission to preserve the environment.
有问题,于是乎,man sudoers,搜索PATH,发现有这么一段:
By default, the env_reset option is enabled. This causes commands to be executed with a new, minimal environment. On AIX (and Linux systems without PAM), the environment is initialized with the contents of the /etc/environment file. The new environment contains the TERM, PATH, HOME, MAIL, SHELL, LOGNAME, USER, USERNAME and SUDO_* variables in addition to variables from the invoking process permitted by the env_check and env_keep options. This is effectively a whitelist for environment variables. Environment variables with a value beginning with () are removed unless both the name and value parts are matched by env_keep or env_check, as they will be interpreted as functions by older versions of the bash shell. Prior to version 1.8.11, such variables were always removed.
那肯定是envreset的锅跑不了了,继续搜索,发现envreset是默认参数行为,这就好办了,到sudoers文件里disable就好了。
因此,sudo visudo,Defaults env_reset改为Defaults !env_reset,保险起见,注释掉Defaults secure_path,注销后生效,问题解决!
p.s. 后来似乎搜到了,PYTHONPATH not working for sudo on GNU/Linux (works for root)
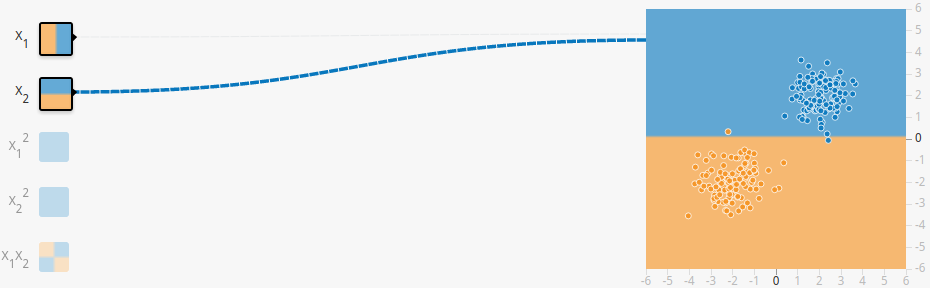
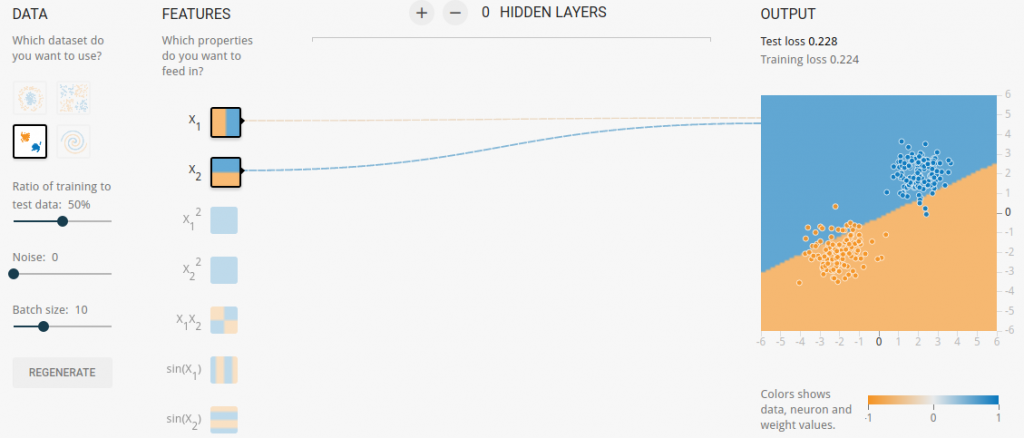 接下来,我们点击第一行的Run开始训练。这个模型应该几秒钟就训练完成了。而且效果非常好,可以清晰的看出dataset已经被明显地按照颜色划分成了两块。
你可能会觉得,What!!发生了什么!!别急,我们接着看。
接下来,我们点击第一行的Run开始训练。这个模型应该几秒钟就训练完成了。而且效果非常好,可以清晰的看出dataset已经被明显地按照颜色划分成了两块。
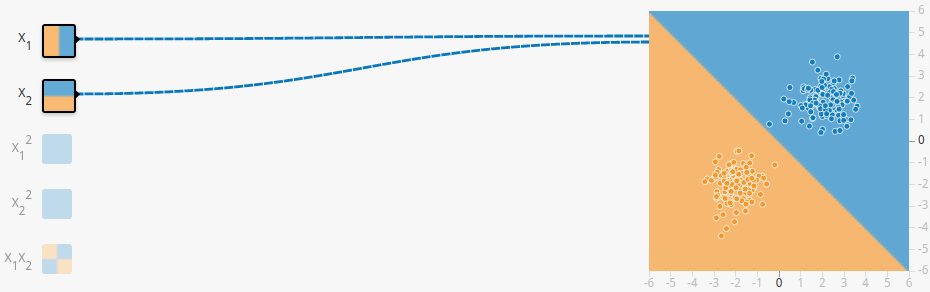
你可能会觉得,What!!发生了什么!!别急,我们接着看。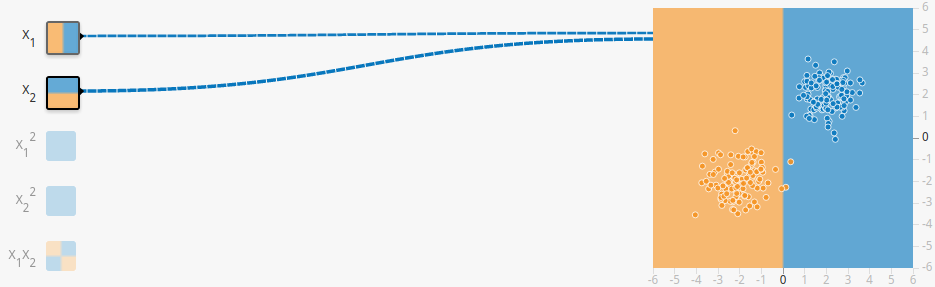 对,这就是第一个feature,竖着“切一刀”!同样,第二个也是“切一刀”,不过是横着罢了。这样简单的“切一刀”就能解决问题吗?显然不能,所以这时时候weight(权重)就是上场了。
weight就是来协调每个“切一刀”切多少的,把每个简单的动作联合起来,共同去解决问题。也就是说:
对,这就是第一个feature,竖着“切一刀”!同样,第二个也是“切一刀”,不过是横着罢了。这样简单的“切一刀”就能解决问题吗?显然不能,所以这时时候weight(权重)就是上场了。
weight就是来协调每个“切一刀”切多少的,把每个简单的动作联合起来,共同去解决问题。也就是说: